The GOBLIN (Global Network on Large-Scale, Cross-domain and Multilingual Open Knowledge Graphs) COST Action held a productive plenary meeting at the Prague University of Economics and Business, bringing together researchers and innovators for two days of collaboration. GOBLIN focuses on creating high-quality, multilingual Knowledge Graphs that are freely available for use, reuse, and redistribution.

During the meeting, some researchers, working the field of NLP and Semantic Web presented their work to motivate our further work within WGs:
Katja Hose (TU Wien) started with the lecture “Introduction to Knowledge Graphs.” She started with data organization and search engines (Google) before Linked Open Data. After that she overviewed open KGs, such as WikiData, Yago, DBPedia, Linked Life Data, PubChem. She explained differences between KGs and Property Graphs. She also pointed out some topic that are active developing, for example near standardization of RDF*, that would enable sentences like: :Kim -> :says -> <<:Katja :likes :Titanic>>. She finished with open venues in Neurosymbolic AI.
In the KG Technologies session, Sebastian Hellman (DBPedia) presented possible impacts of Linked Data to AI requessts. He also presented recent developments of DBPedia and introduction of global IDs for entities in DBPedia. Jose Emilio Labra Gayo (University of Oviedo) explained differences between SHACL and ShEx. He also wrote a book on validation of RDF data – kgbook.org. He especially pointed out that validation techniques are important for documenting KGs, summarizing KGs and generating UIs for KGs.
During the second day, Kathrin Dentler (eccenca) reviewed 20 Years of Knowledge Graphs, starting from her PhD study. Mehwish Alam (Institut Mines-telecom) focused on KGs and embeddings. She referred to a known linguistic notion that “word is defined by the company it keeps.” The same should hold for graph data (i.e., linked data). Jan-Christoph Kalo (University of Amsterdam) followed with the presentation LLMs and KGs – A promising symbiosis. He pointed out that LLMs are bad at reasoning, but they might get help from the Linked Data. Also, in the future, they might be crucial for KG maintenance. Gilles Sérasset (Université Grenoble Alpes) concluded with presentation of DBnary. It is a great lexical resource where we can see the data and history of the data for each participating language.
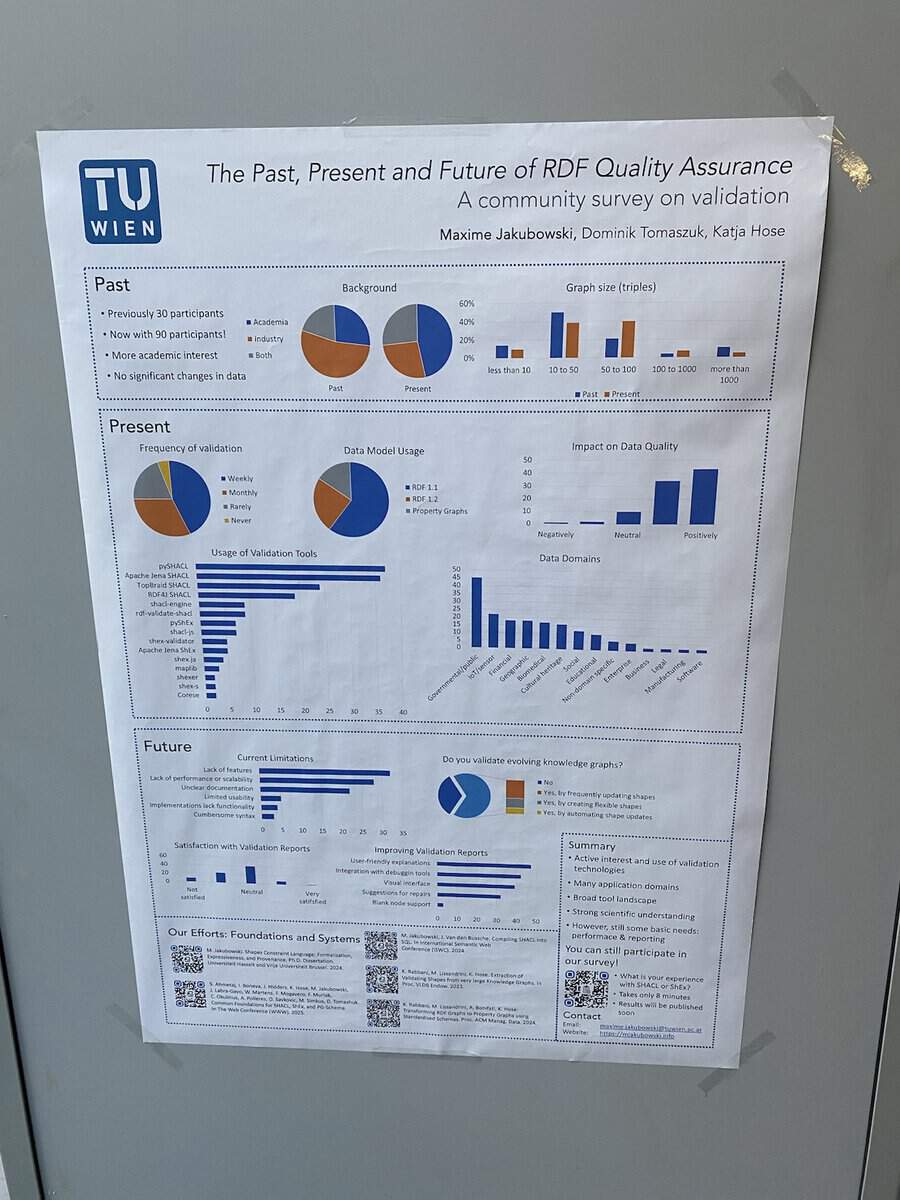
A large part of the meeting was devoted into bootstrapping the Working Groups:
WG1: Knowledge graphs engineering: modelling, knowledge extraction, integration and interlinking, enrichment, publishing and release management.
WG2: Knowledge Graphs Management: Data Quality Assurance, Metadata and Provenance, KG Refinement, Knowledge Exploration, Security and Privacy, Mining KGs.
WG3: Knowledge Graph-aware Services and Methods: KGs and Language Models, KGs and Machine Translation, KGs and Question Answering, KGs and Information Retrieval.
WG4: Use Cases and Applications: WG leaders asked participants to propose use cases and 17 use cases were submitted. After that, the idea is that we select less topic that might cover all the proposed use cases.
The second day after lunch I started my journey back home. I was driving with my car and I attended the MC Meeting online.
I am eager to collaborate with colleagues that I was working with already in COST Action Nexus Linguarum. I am also thankful to Milan Dochinovski, the Action Chair, who invited me to join the Action. Below I include some images, and also poster shots: